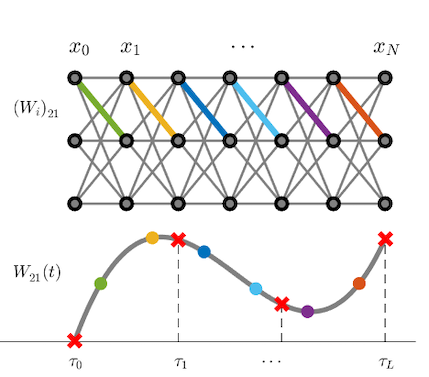
Surveillance evasion through Bayesian reinforcement learning
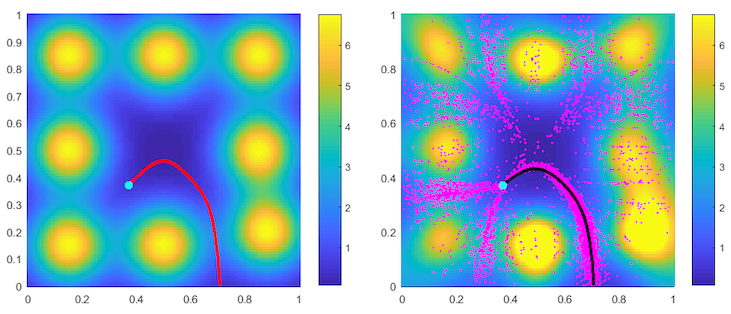
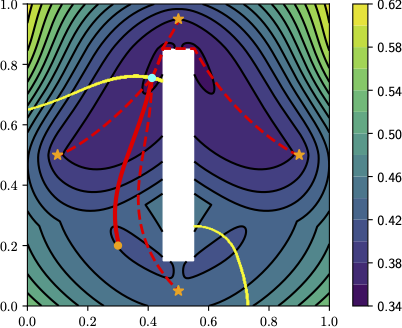
In surveillance evasion game, what if the surveillance intensity is a priori unknown but has to be learned on-line, as the evader conducts repetitive path planning? Is there a strategic method to explore the relevant regions?