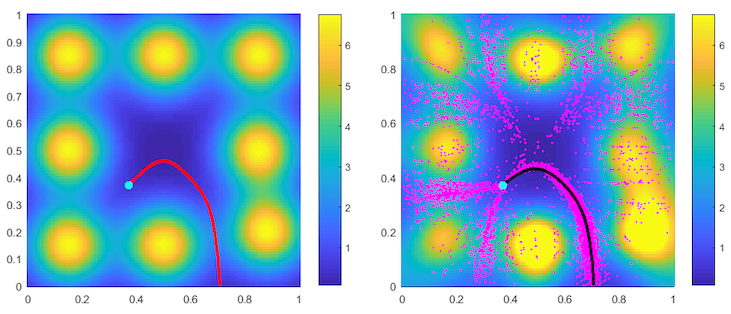
Surveillance evasion through Bayesian reinforcement learning
Suppose an Evader is trying to escape a domain (the unit square in the following figure) while minimizing the cumulative risk of detection (termination) by adversarial Observers. Those Observers’ surveillance intensity (whose heatmap is shown in the background of the left figure) is a priori unknown and has to be learned through repetitive path planning. This is a model-based reinforcement learning (RL) problem in which information comes in a sequence of consecutive episodes.
In this project, we developed a a new algorithm that utilizes Gaussian process regression to model the unknown surveillance intensity and relies on a confidence bound technique to promote strategic exploration. We illustrate our method through several examples and confirm the convergence of averaged regret experimentally.
Joint work with Prof. David Bindel and Prof. Alexander Vladimirsky.